- 发布于
记录一次niconico直播弹幕的逆向(?)过程
- 记录一次niconico直播弹幕的逆向(?)过程
省流
弹幕数据的入口地址是在直播时的websocket连接中获取的
弹幕相关数据是通过protobuf进行序列化的
目前yt-dlp的开发者正在实现比较通用的python protobuf库,名字叫做protobug
相关issue: #12494
如果有获取弹幕的需求,可以使用issue中maintainer提到的工具( ニコ生新配信録画ツール(仮)进行提取弹幕数据。同样的,此工具是开源的,地址在github。
- 压制工具推荐
- Danmaku2ass: 支持多种格式的xml弹幕文件转为ass字幕
-f FORMAT, --format FORMAT Format of input file (autodetect|Niconico|NiconicoYtdlpJson|NiconicoYtdlpJson2|Acfun|Bilibili| Bilibili2|Tudou|Tudou2|MioMio|DanDanPlay) [default: autodetect]- shiori: 基于Rust编写的HLS/MPEG-Dash的下载器,支持点播(Vod)和直播,以及niconico的直播弹幕提取。
- SanaEncoder: 非常高效的基于FFmpeg的音视频编码工具,可压制字幕,支持unicode字符。(因为我拿好几年前的小丸工具箱压制弹幕出现了乱码)
正文
接下来会以流水账的方式来记录下逆向的过程。
要说逆向,其实也不算是逆向,毕竟代码逻辑都在前端的js中,还好niconico的js代码没有做混淆,大体逻辑都还能看的很明白。
动机
被站内大佬问了能不能提供弹幕版本的直播回放。在网上搜了半天没有搜到相关的工具/开源实现,最后决定自己动手。但实际上一开始看到过文中一开始提到的yt-dlp的issue,但没有点进maintainer回复中提到的工具。
1. 搜索是否有现成的工具
在动手之前为了避免重复造轮子,先搜索了很多相关的工具。比如yt-dlp、streamlink、shiori(写本篇文章的时候翻源代码才发现作者老早就支持了nicolive的弹幕🫡)
在yt-dlp的源码中,看到niconico的弹幕代码只针对视频,即链接为 https://www.nicovideo.jp/watch/sm123456 的形式进行处理。简单来说,视频的弹幕可以从一个接口(关键词为:threads)中获取。
但是直播中搜索可能的弹幕以及threads接口,发现并没有相关的接口。
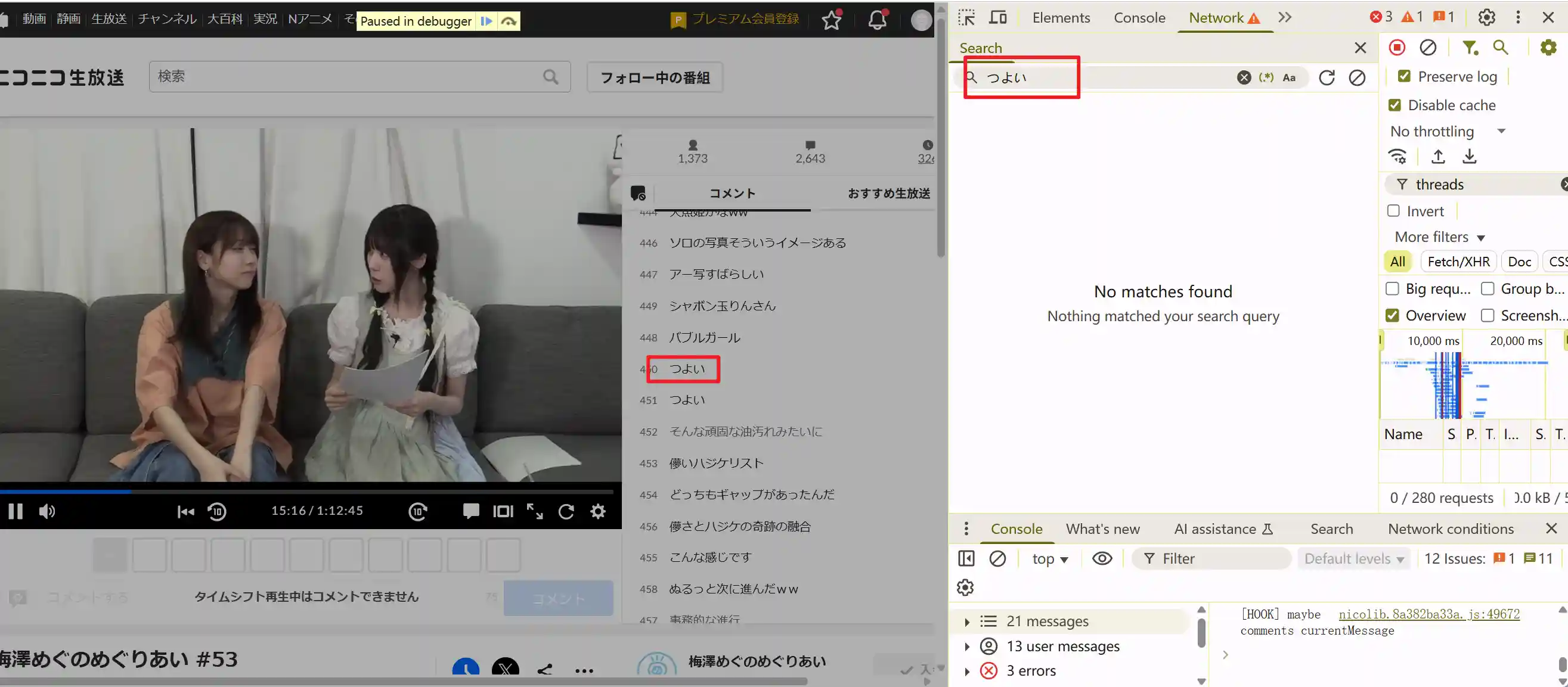
但是弹幕数据只能通过请求获取,那么一定是通过其他方式获取弹幕数据的。
2. 通过浏览器的Network面板进行详细搜索
翻看请求,除了常规的流媒体请求以外,还发现了如下网址的请求:
内容如下

发现其中有 https://x.com/kusururindesu ,那么把这一串二进制转为hex字符串扔给llm分析

那么确定这些数据就是弹幕数据
3. 查看源码解析二进制数据
本人阅历太少,对这些二进制格式还没能做到一眼看出来的能力。不确定是不是 protobuf(这个后面要考) 之类的。所以打算尝试通过翻看js代码来找关键解析代码进行提取。
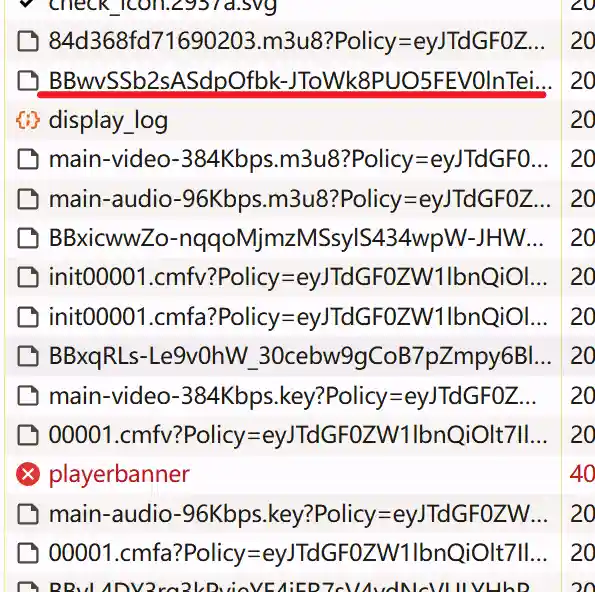
所以第一步是要弄明白这个链接是怎么来的。 于是找到了万物根源: https://mpn.live.nicovideo.jp/api/view/v4 的请求。
这个链接在F12搜也没搜到,不过有一个前置背景是niconico的直播的流媒体地址是通过websocket获取的,具体的源码实现可以参考yt-dlp/streamlink/iori等工具。
于是通过messageServer的包获取到了此链接来源
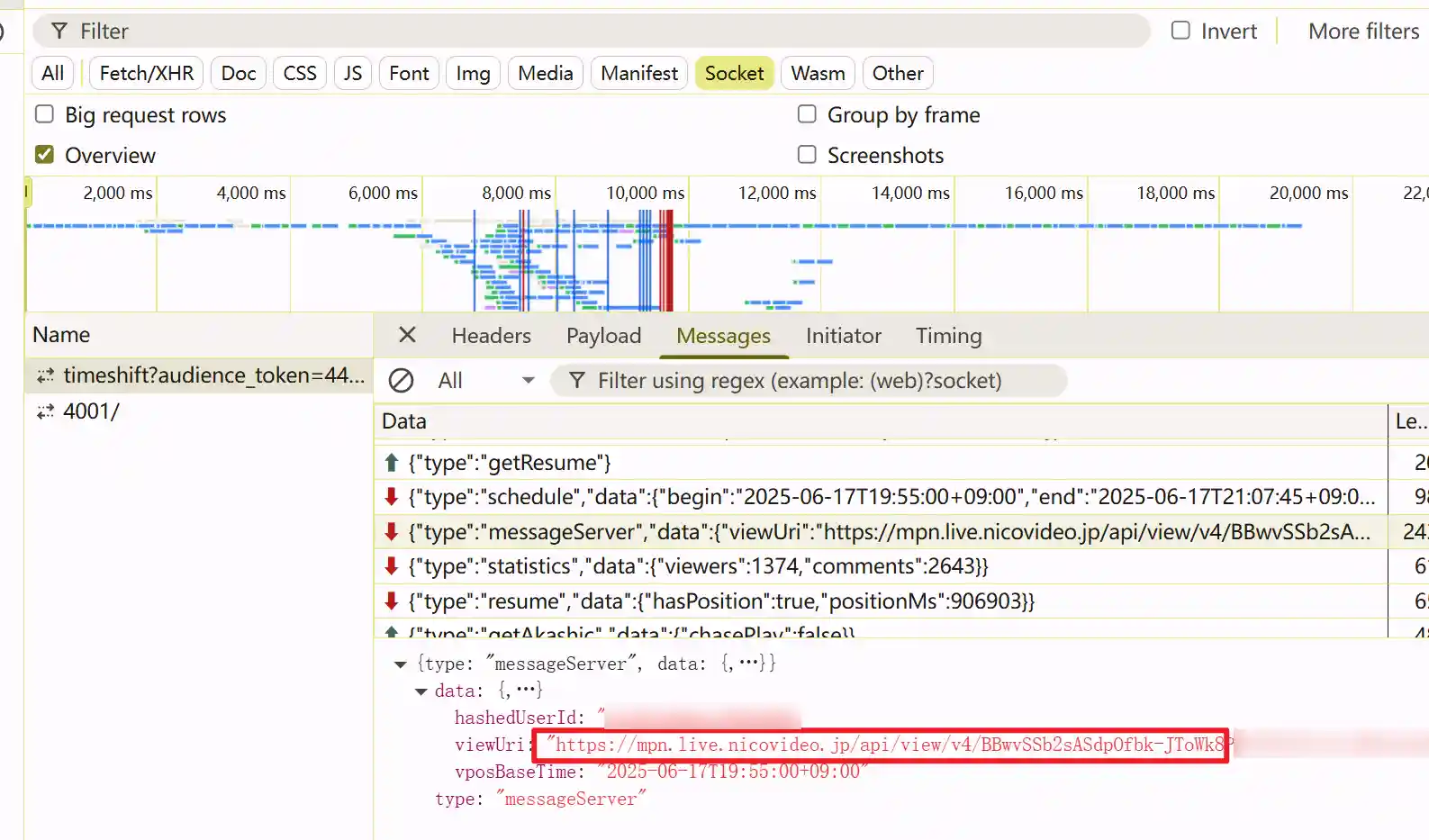
接着在所有的网络请求中搜索关键词 messageServer,结果可以发现在许多js文件中都有相关代码。不过第一个的js文件是comment-render,感觉和弹幕评论区有关,就先从这里入手。

运气也是很好,再点击几个函数上下翻后,发现了有叫chatList的变量。这很好啊,立马开始print调试+断点。
很明显就是这就是弹幕列表了,不过看了下这个是增量更新,应该是与直播中弹出来的最新弹幕有关?不管了,我们主要任务是解析二进制,获取格式化的弹幕数据。
查看函数调用栈
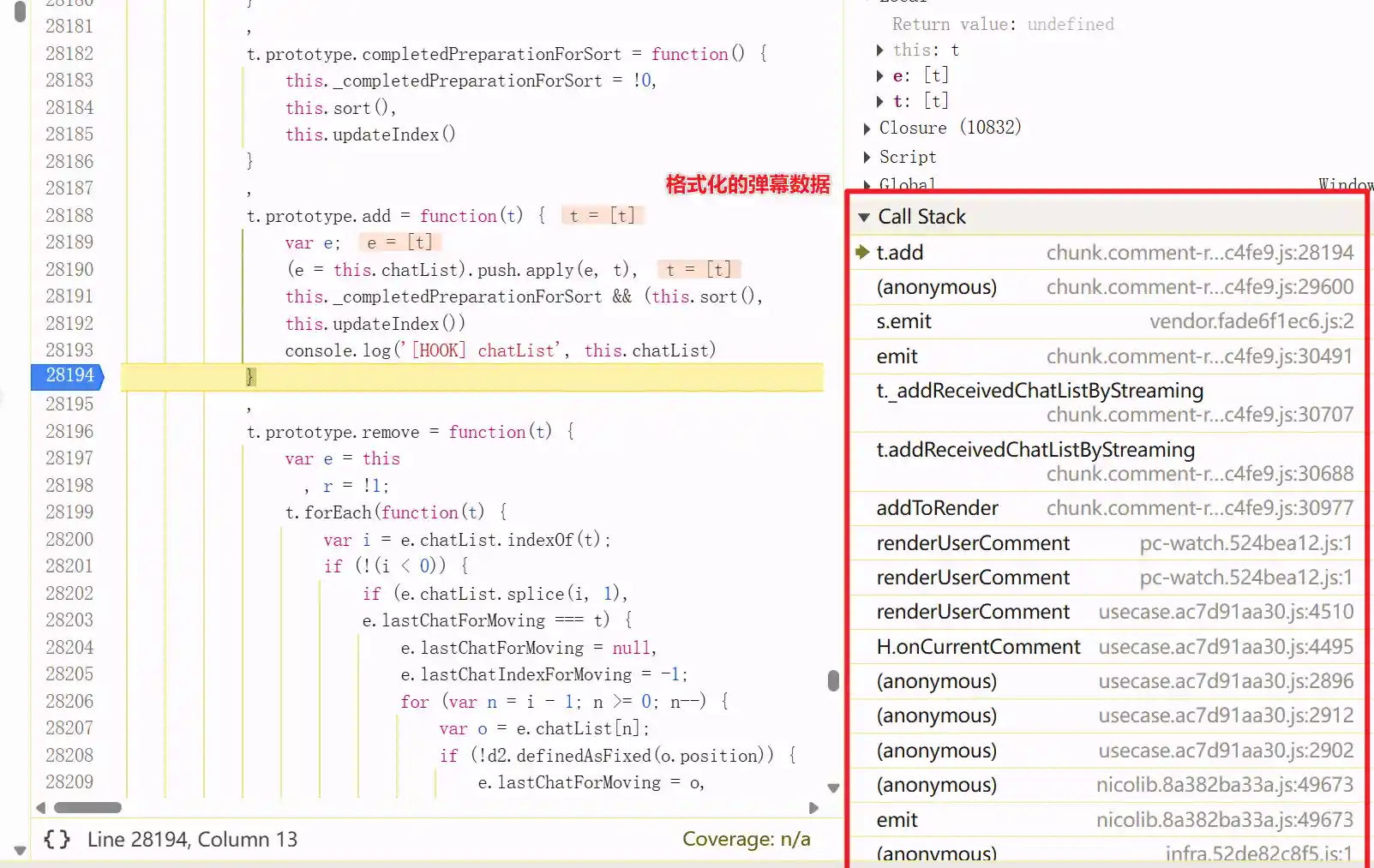
看到了这个,原来这串字符是id,但是我们要看这个数据是怎么产生/解析的
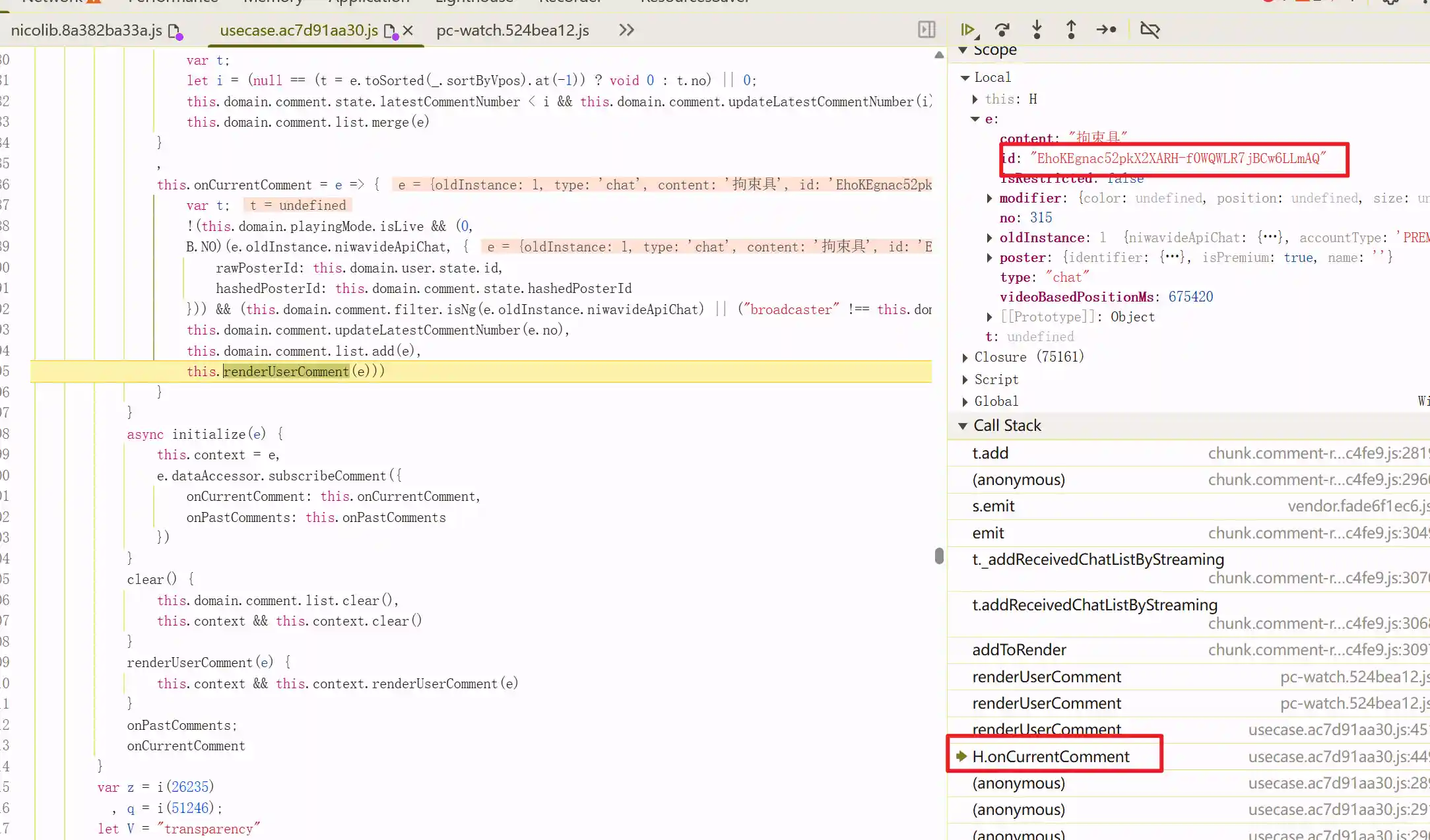
再往下一路追到了这里,监听了名字为currentMessage的事件,然后提供当前最新的弹幕
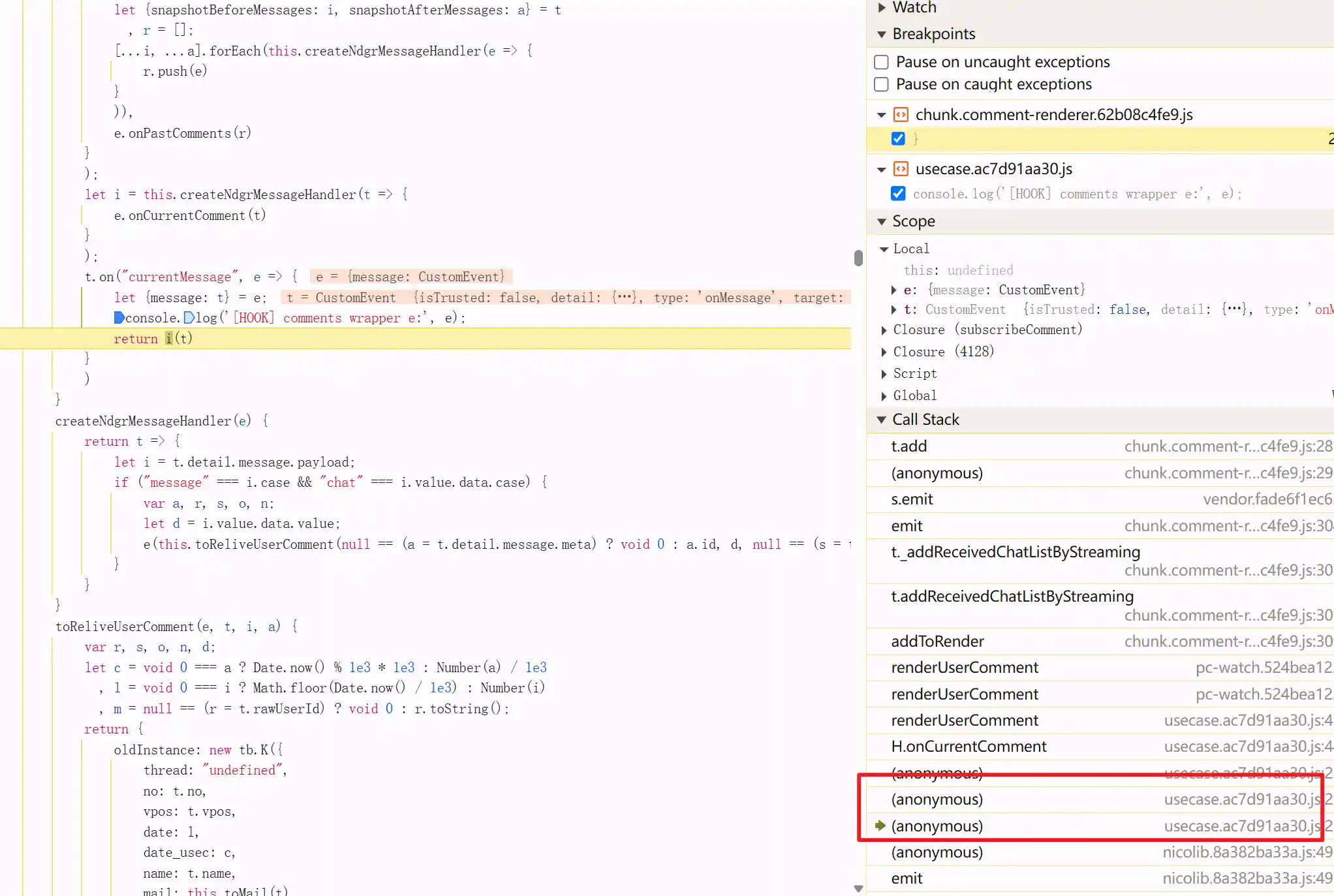
那么搜索currentMessage是被谁emit了,根据函数调用栈,找到了此处 nico直播弹幕类
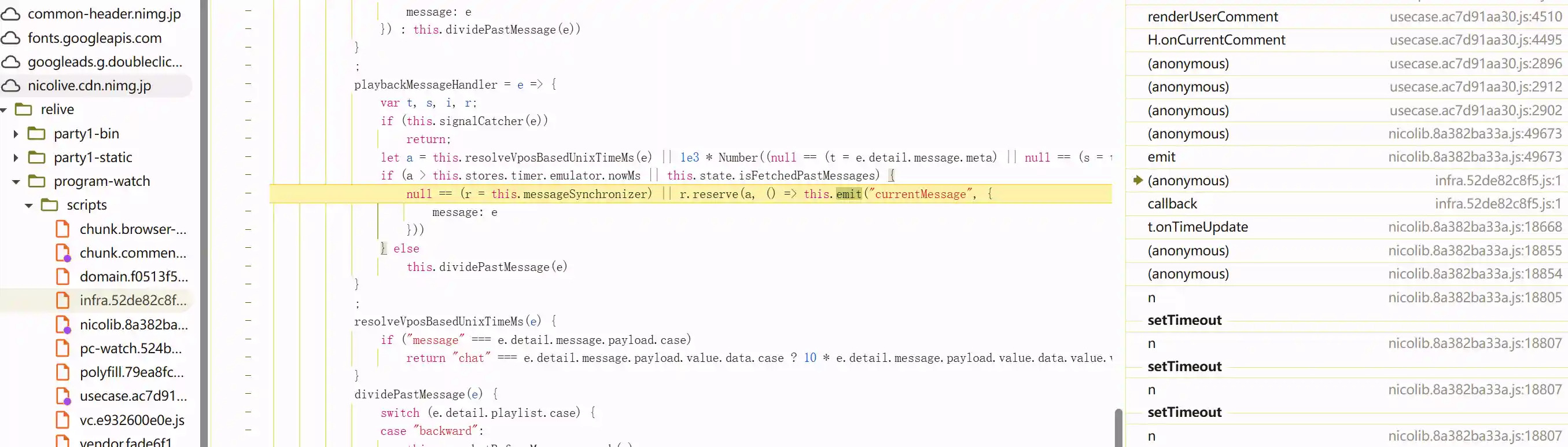
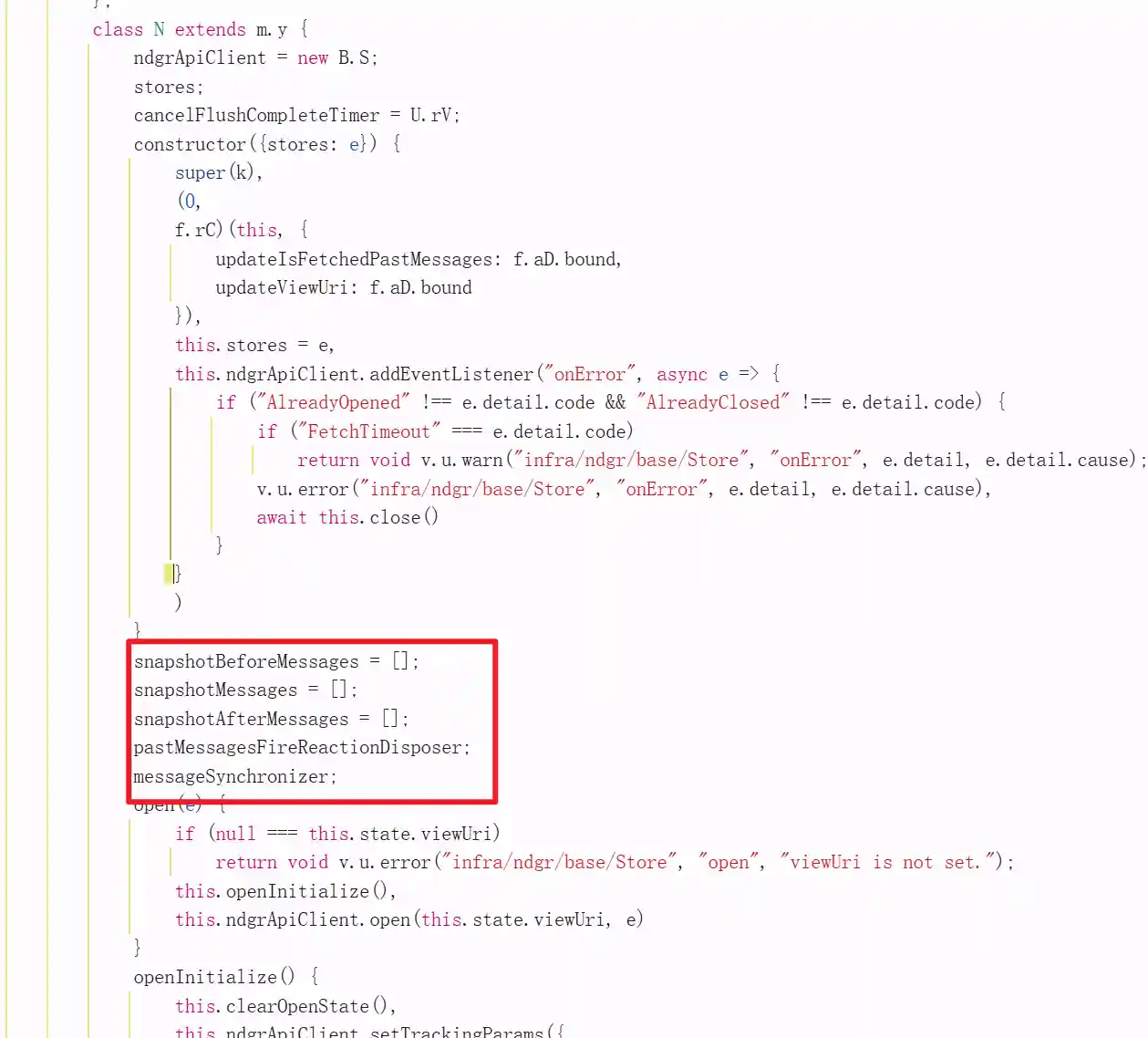
viewUri与websocket中的viewUri能够对应的上,以及其中的snapshot和backward关键词都是在上面提到的请求中出现了的。
仔细查看可以发现是由原来是ndgrApiClient提供的onMessage以及解析后的弹幕数据
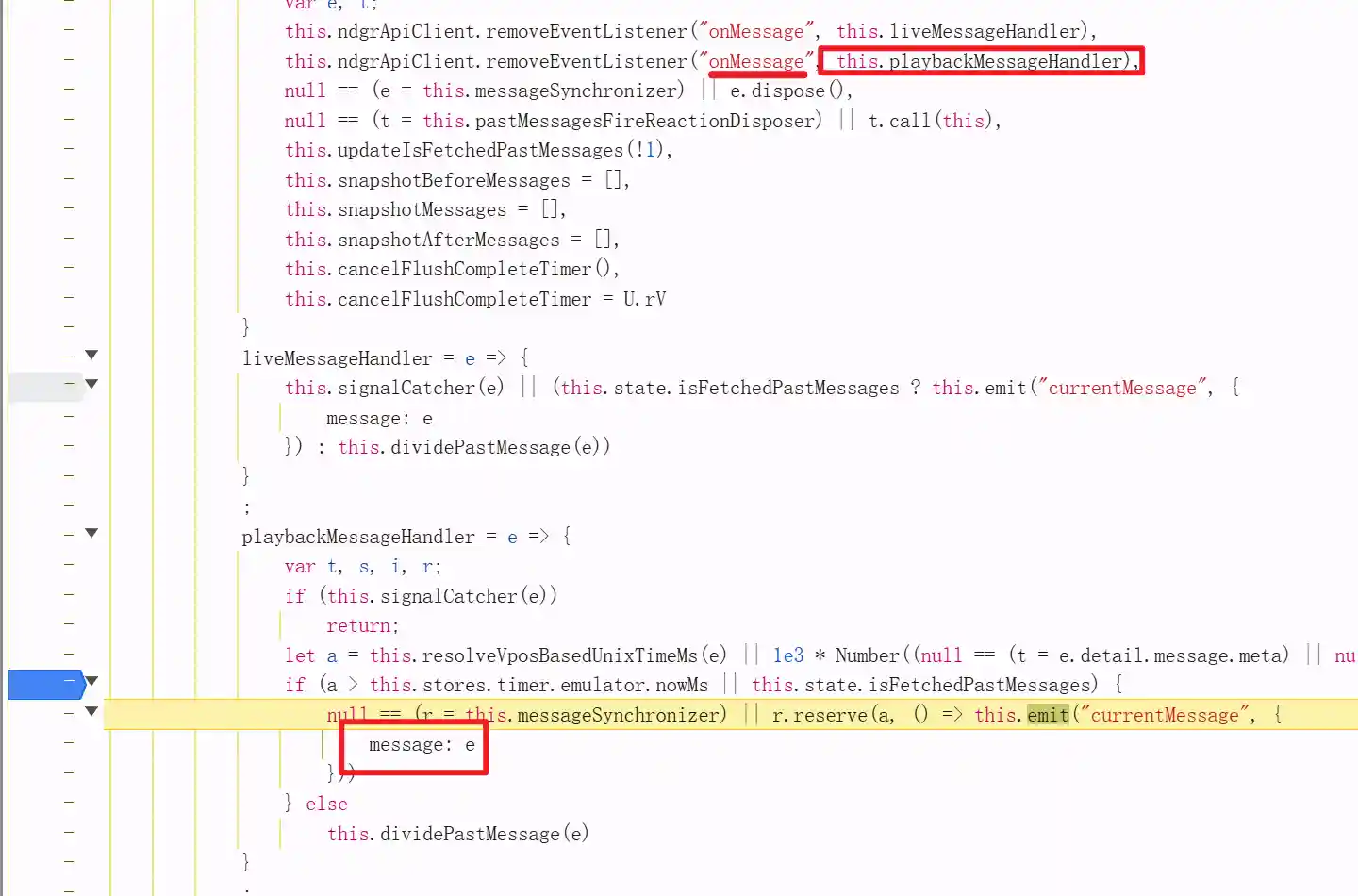
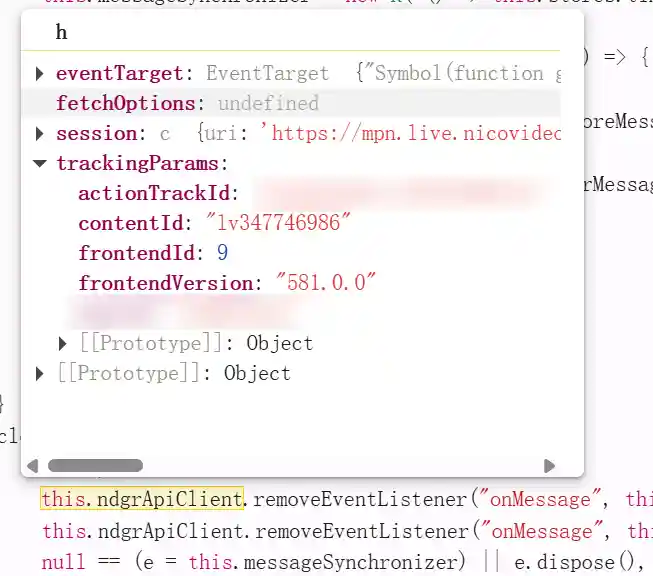
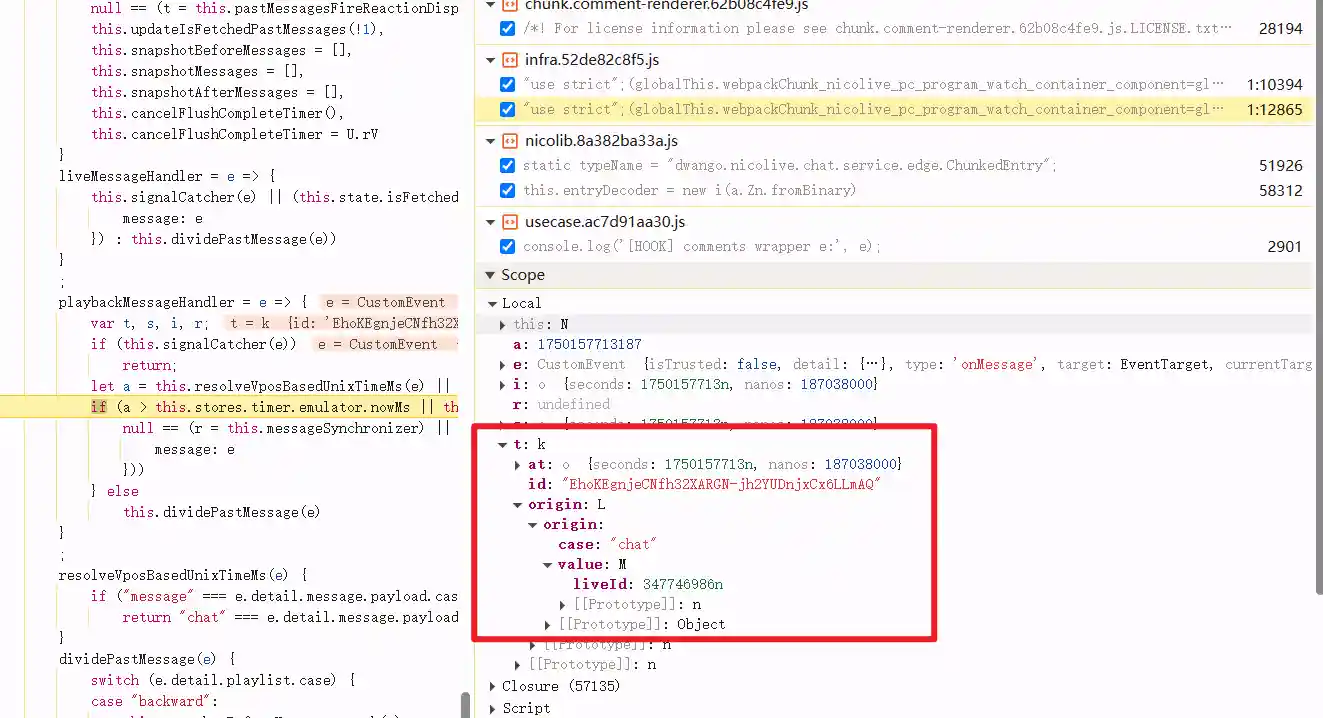
仔细查看这个实例,可以发现session中除了onMessage之外还有一个entryDecoder的成员变量,其中buffer长度是910Bytes,再结合浏览器返回的数据,可以发现一模一样,这更是令我欢喜。
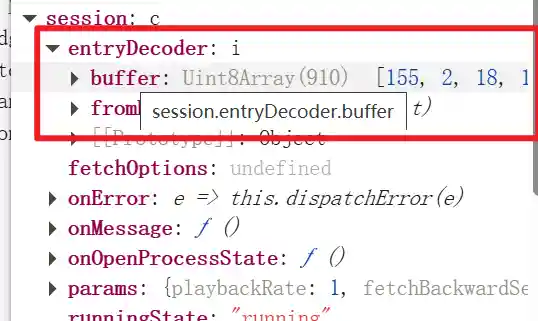
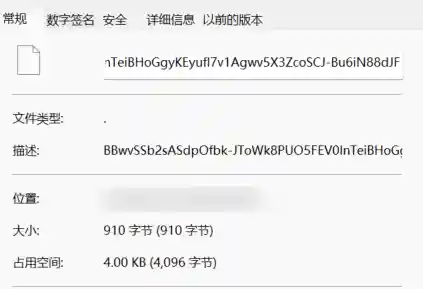
前几字节的对比
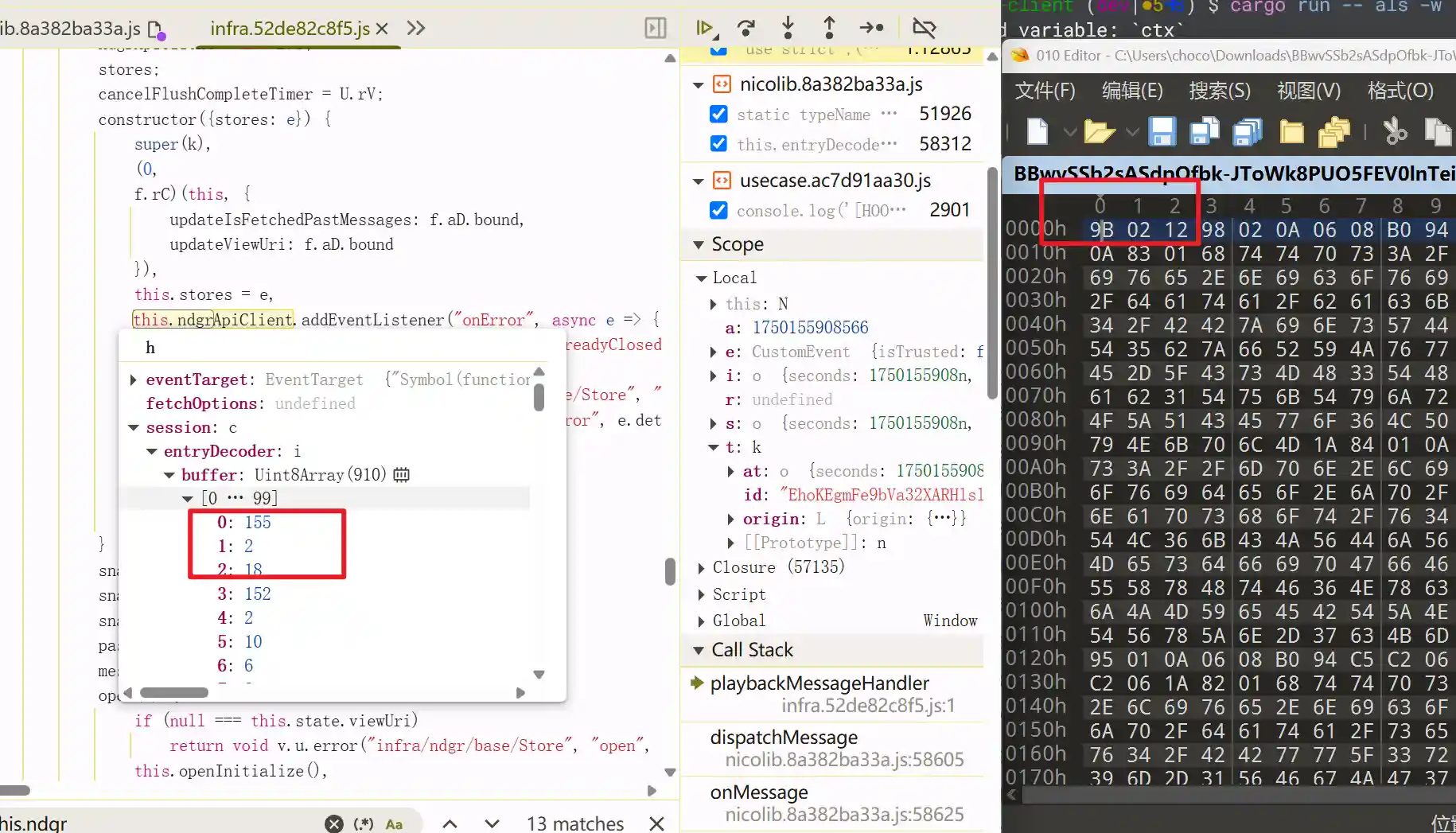
继续搜索entryDecoder的逻辑是什么
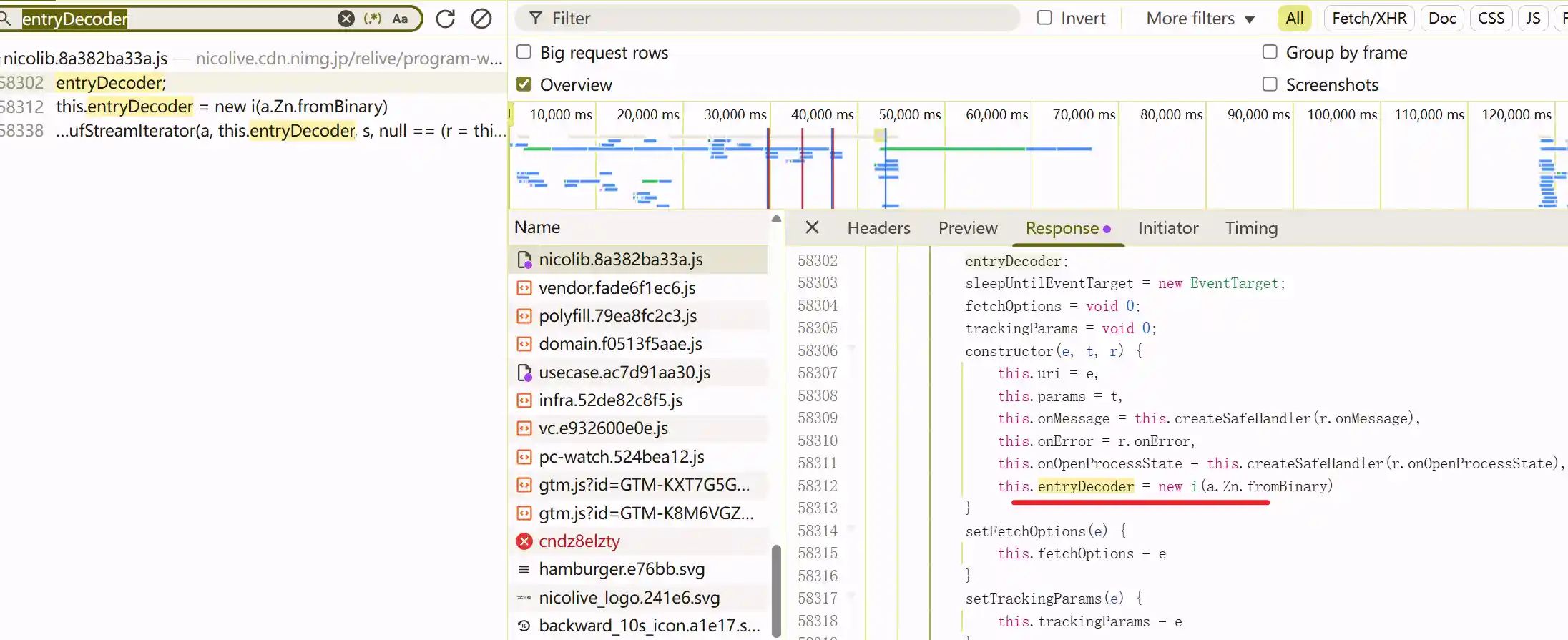
打个断点先
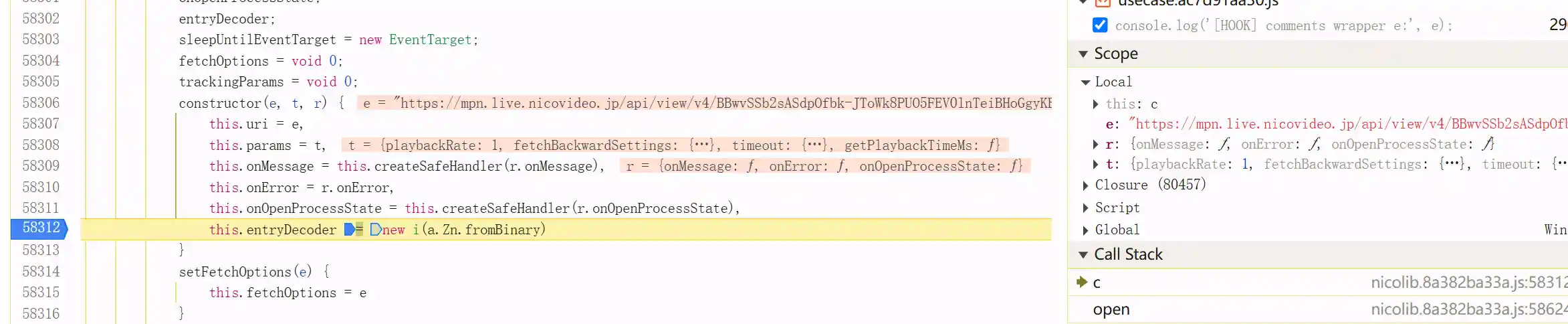
点进去看看原型
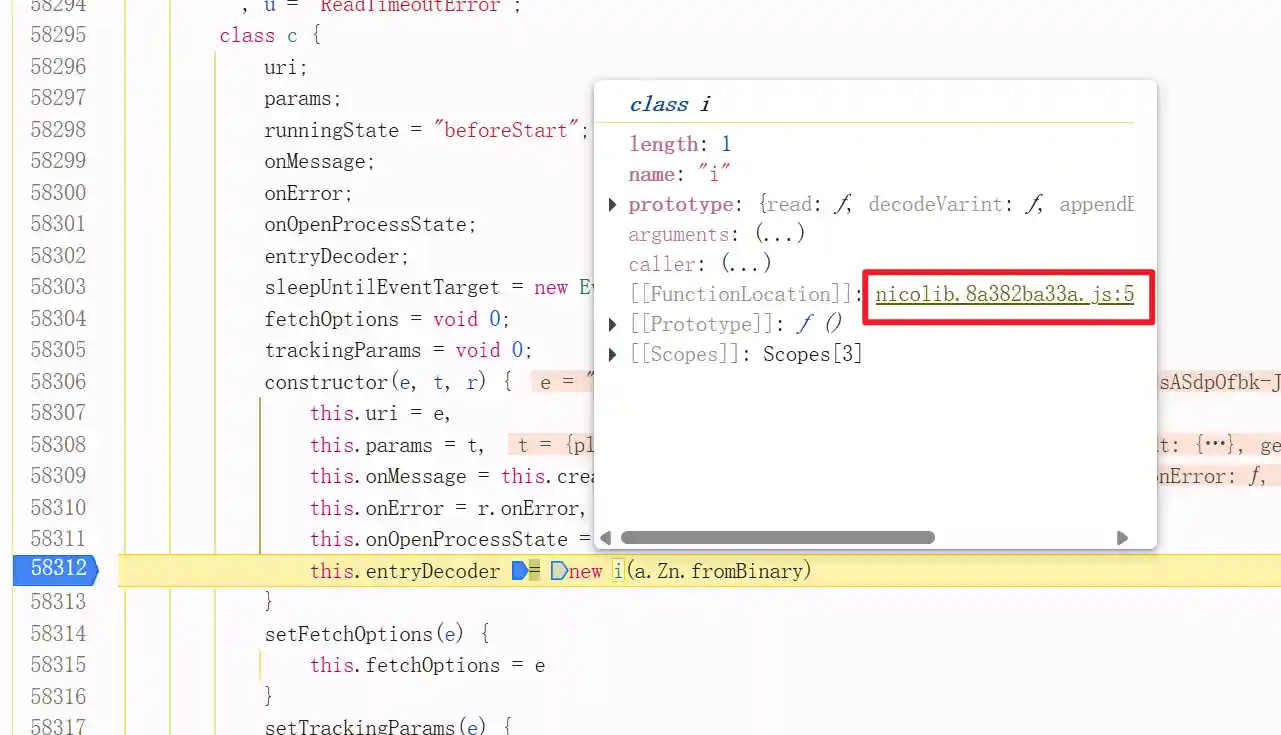
代码基本清晰明了,接下来可以本地启动nodejs运行/喂llm来解析这串代码是什么意思了。
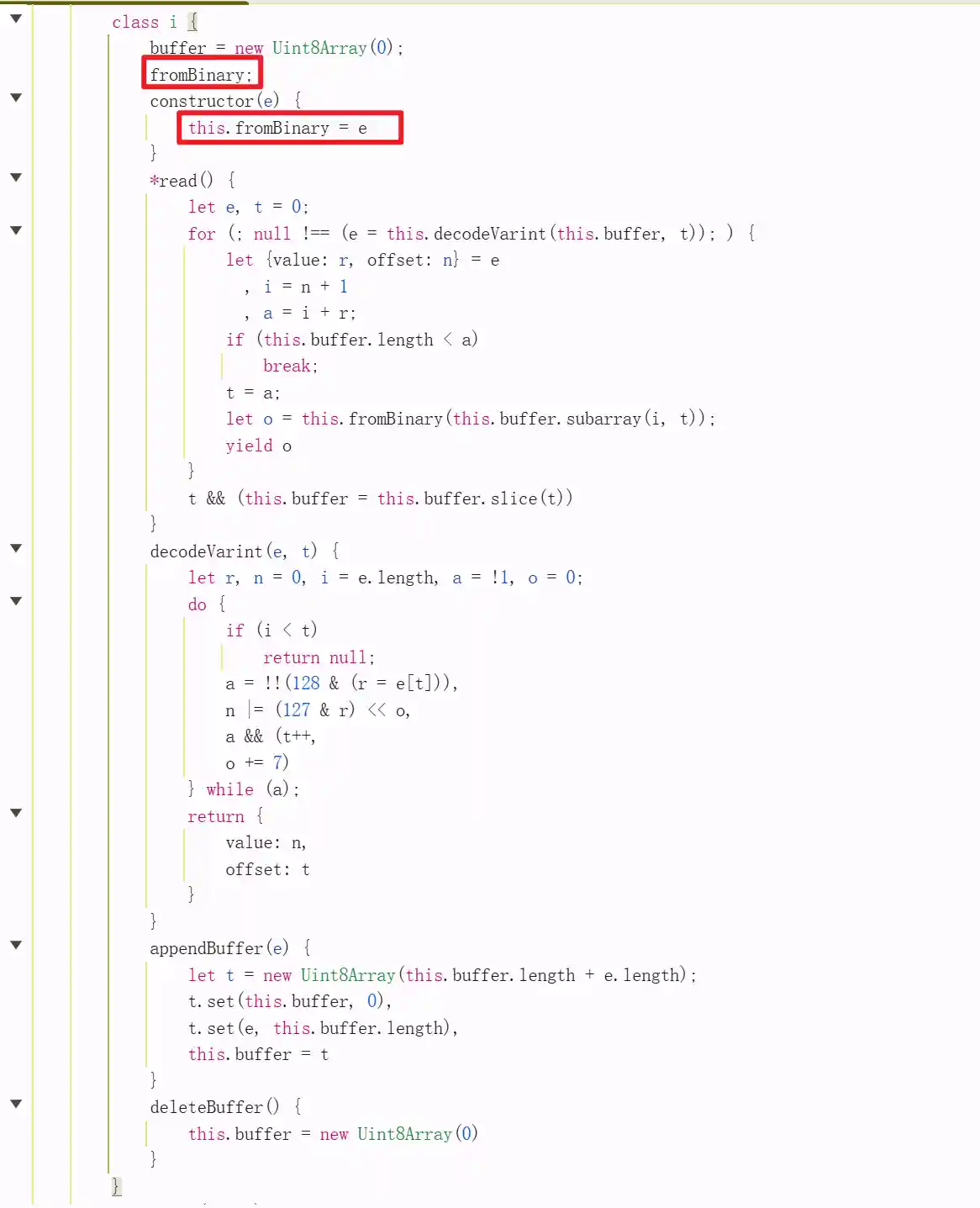
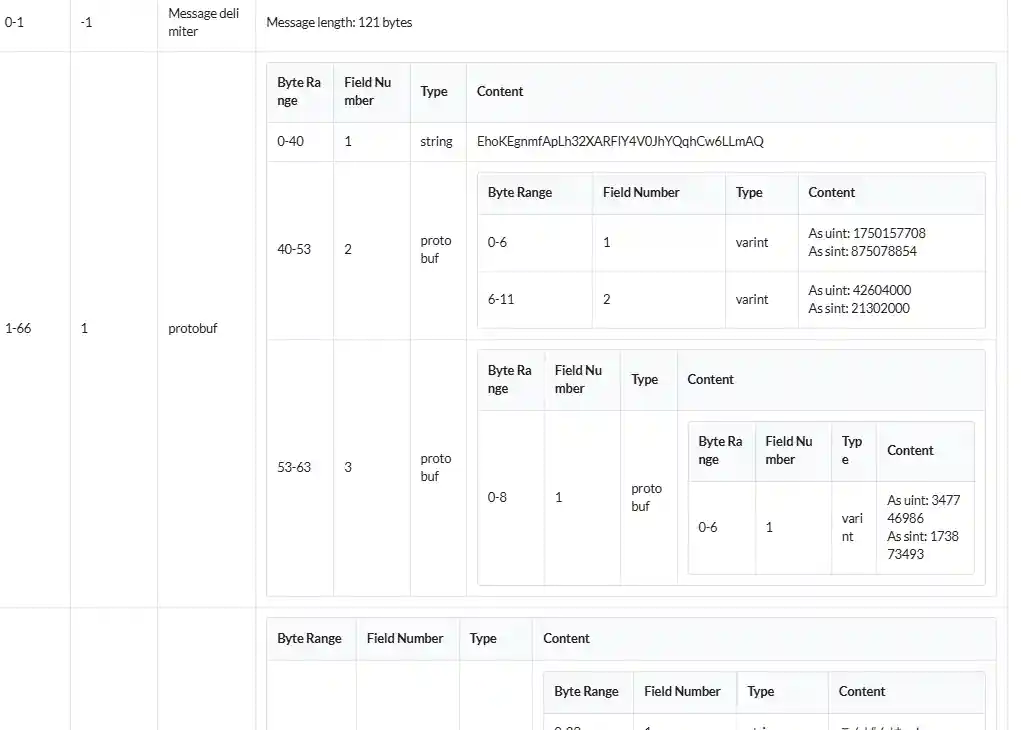
这个decodeVariant非常像protobuf的玩意儿啊,于是我们可以发现(llm发现的)这个16进制第一个字节与包长度有关(protobuf的解析方式),后面是protobuf数据,于是我们把数据放进protobuf解析网站上 https://protobuf-decoder.netlify.app/ 结合前端调试,验证了我们的想法。
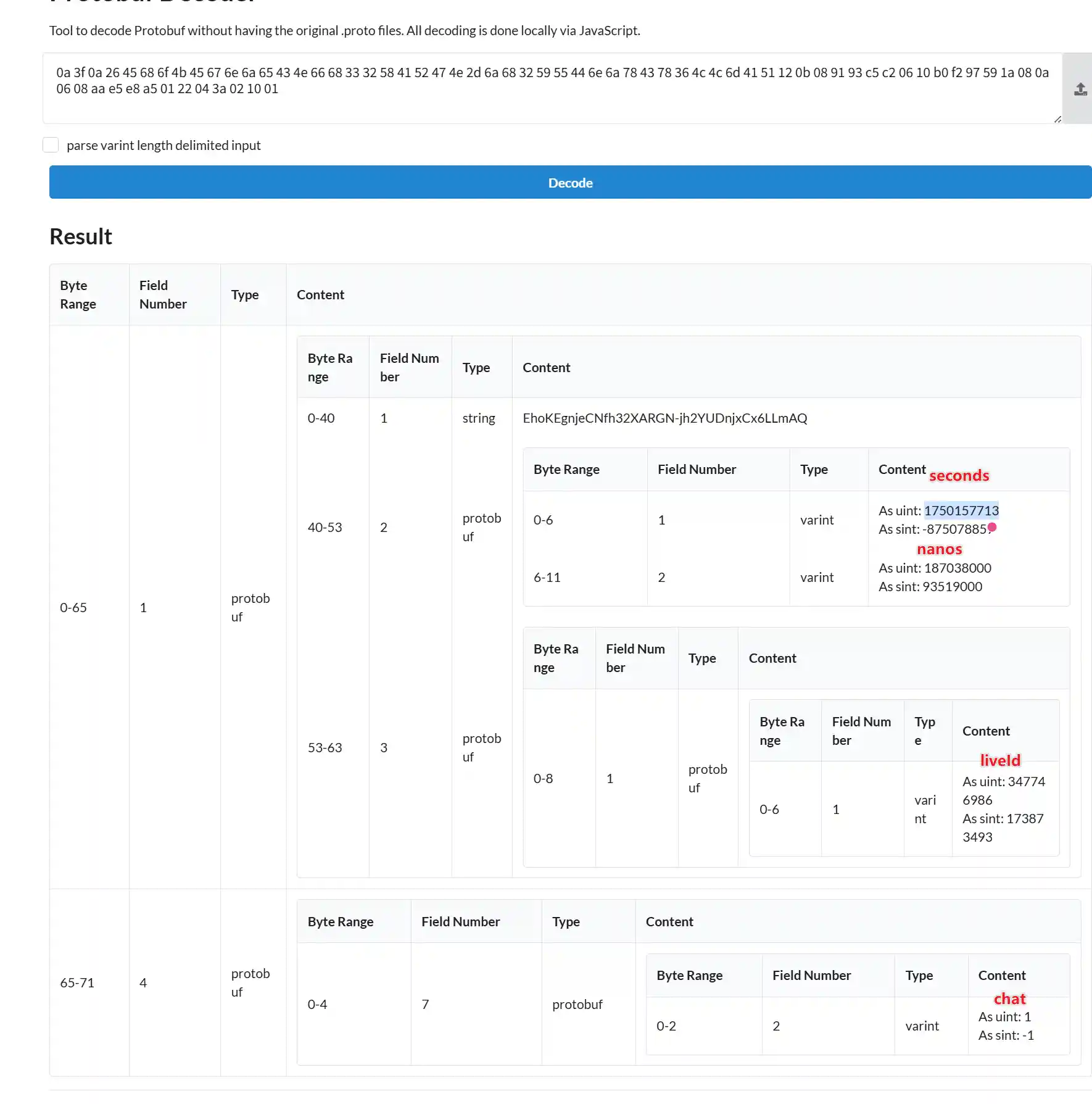
查看protbuf解析,可以看到弹幕内容和发送偏移量元信息。
元信息与文本内容和视频的偏移(671 / 100) 秒,右侧图最下面的是弹幕序列号。
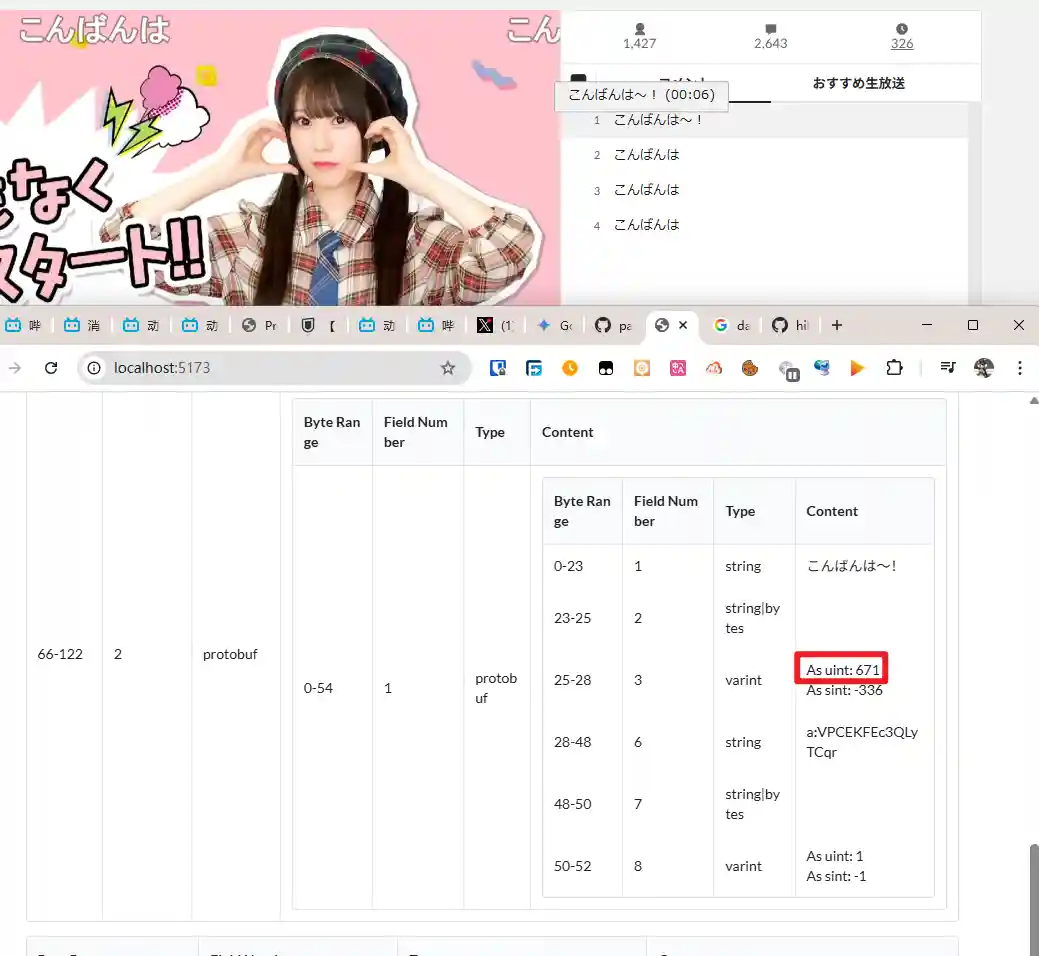
这是运营弹幕,不过运营弹幕会少一些数据,但是可以通过元信息以及第一个用户弹幕来计算vpos,问题不是很大。
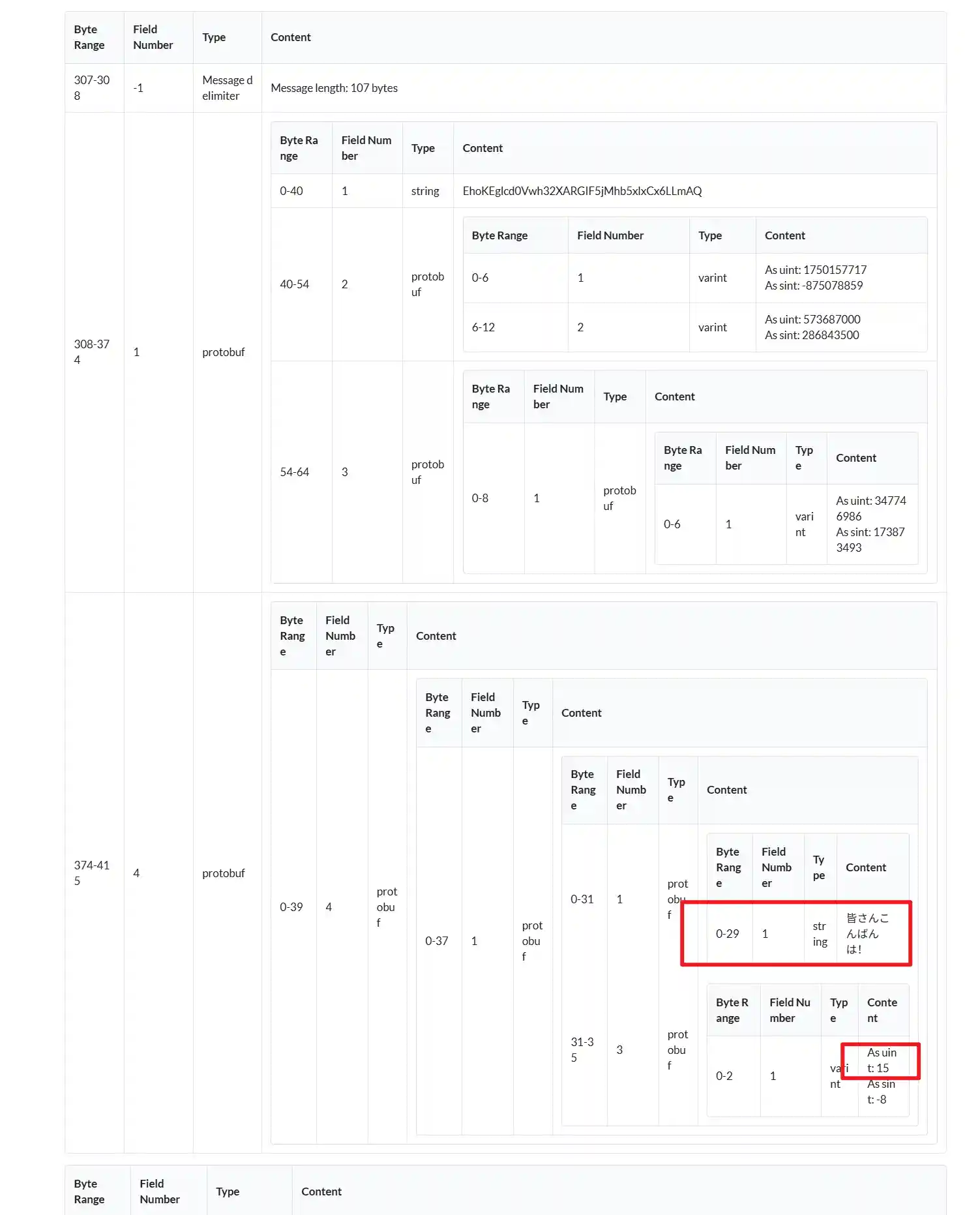
弹幕内容分析基本完毕
4. 如何获取所有的弹幕数据
接下来就是寻找如何遍历所有的弹幕,并下载保存。逻辑很明了,从最开始的view/v4接口中获取弹幕数据。
主要分为三种:
- backward:对提取弹幕来说没什么用
- snapshot:对提取弹幕来说没什么用
- segment:弹幕数据
view地址根据其携带的时间戳来获取不同的数据。此外当前似乎并不需要鉴权。
query 参数如下:
- at: 时间戳,单位为秒,经分析发现范围是直播开始到活动结束的时间戳,步长为30±3秒。
- WpXb:base64,里面有跟踪id,目前不提供也行。
由于不需要鉴权,可以通过aria2c直接尝试下载。
- 活动开始时间戳 1750157700 18:55:00 开始
- 活动结束时间戳 1750162065 20:07:45 结束
- 持续时间 1:12:45
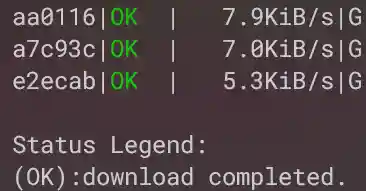
aria2c.exe -Z -P "https://mpn.live.nicovideo.jp/api/view/v4/<path>?at=17501[57700-62065:30]"
非常完美,下载了146个文件
接下来就是编码protobuf解析,并且获取所有的segment网址,然后批量下载segment,分析两大类弹幕
用户弹幕,用户弹幕至少保留offset,发布时间戳,内容
运营弹幕,根据用户弹幕计算offset,发布时间戳,内容
然后最后保存到合适格式的文件中,比如xml用于danmaku2ass之类的开源工具。
5. 结尾
既然需求这么明确了,那么我们就有请llm老师来帮我们编写脚本。这里使用的语言是python(本次就不用rust语言了),因为后续可能会将此功能提pr至yt-dlp/streamlink等开源工具上去。
不过,当我为yt-dlp写到70%的功能时,对代码质量产生了相当大的疑惑,因为protobuf的解析代码实现的不是非常优雅。于是在朋友的建议下,去yt-dlp的官方discord进行讨论,讨论结果如下。
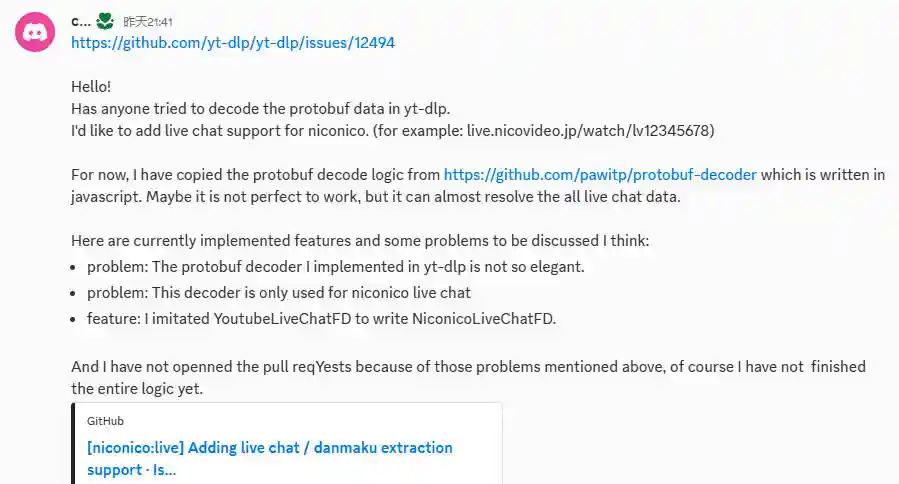
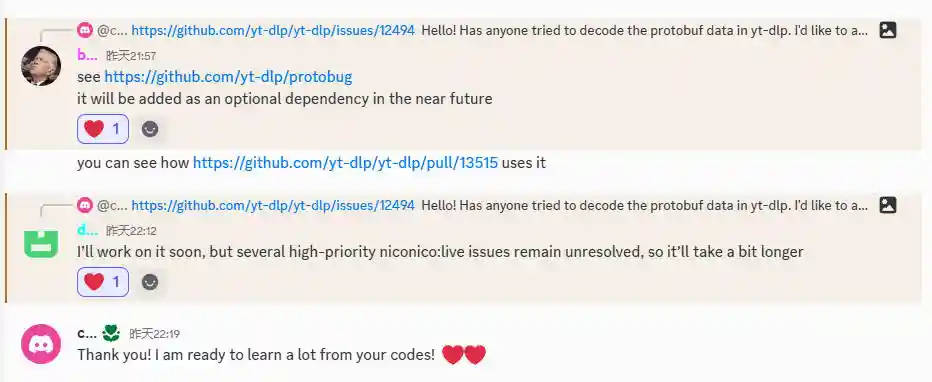
(maintainer回复的好快!python高手!)
那我就不重复造轮子了,况且代码质量堪忧。那么接下来就花精力到林库拉的逆向工作中去吧()!
分享